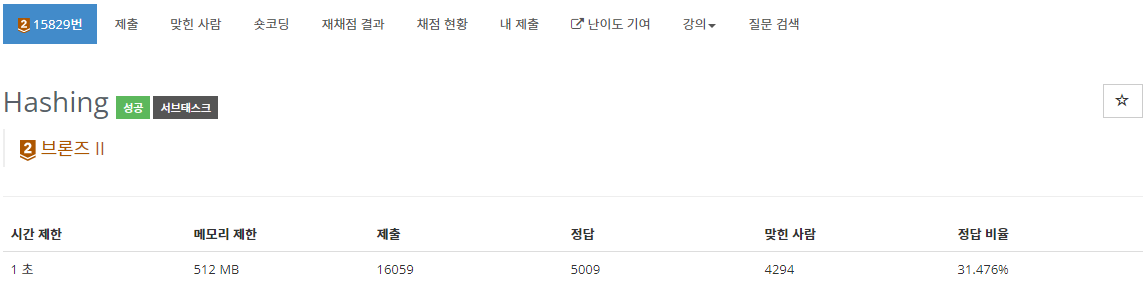
문제
APC에 온 것을 환영한다. 만약 여러분이 학교에서 자료구조를 수강했다면 해시 함수에 대해 배웠을 것이다. 해시 함수란 임의의 길이의 입력을 받아서 고정된 길이의 출력을 내보내는 함수로 정의한다. 해시 함수는 무궁무진한 응용 분야를 갖는데, 대표적으로 자료의 저장과 탐색에 쓰인다.
이 문제에서는 여러분이 앞으로 유용하게 쓸 수 있는 해시 함수를 하나 가르쳐주고자 한다. 먼저, 편의상 입력으로 들어오는 문자열에는 영문 소문자(a, b, ..., z)로만 구성되어있다고 가정하자. 영어에는 총 26개의 알파벳이 존재하므로 a에는 1, b에는 2, c에는 3, ..., z에는 26으로 고유한 번호를 부여할 수 있다. 결과적으로 우리는 하나의 문자열을 수열로 변환할 수 있다. 예를 들어서 문자열 "abba"은 수열 1, 2, 2, 1로 나타낼 수 있다.
해시 값을 계산하기 위해서 우리는 문자열 혹은 수열을 하나의 정수로 치환하려고 한다. 간단하게는 수열의 값을 모두 더할 수도 있다. 해시 함수의 정의에서 유한한 범위의 출력을 가져야 한다고 했으니까 적당히 큰 수 M으로 나눠주자. 짜잔! 해시 함수가 완성되었다. 이를 수식으로 표현하면 아래와 같다.
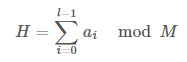
해시 함수의 입력으로 들어올 수 있는 문자열의 종류는 무한하지만 출력 범위는 정해져 있다. 다들 비둘기 집의 원리에 대해서는 한 번쯤 들어봤을 것이다. 그 원리에 의하면 서로 다른 문자열이더라도 동일한 해시 값을 가질 수 있다. 이를 해시 충돌이라고 하는데, 좋은 해시 함수는 최대한 충돌이 적게 일어나야 한다. 위에서 정의한 해시 함수는 알파벳의 순서만 바꿔도 충돌이 일어나기 때문에 나쁜 해시 함수이다. 그러니까 조금 더 개선해보자.
어떻게 하면 순서가 달라졌을 때 출력 값도 달라지게 할 수 있을까? 머리를 굴리면 수열의 각 항마다 고유한 계수를 부여하면 된다는 아이디어를 생각해볼 수 있다. 가장 대표적인 방법은 항의 번호에 해당하는 만큼 특정한 숫자를 거듭제곱해서 곱해준 다음 더하는 것이 있다. 이를 수식으로 표현하면 아래와 같다.
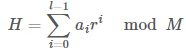
보통 r과 M은 서로소인 숫자로 정하는 것이 일반적이다. 우리가 직접 정하라고 하면 힘들 테니까 r의 값은 26보다 큰 소수인 31로 하고 M의 값은 1234567891(놀랍게도 소수이다!!)로 하자.
이제 여러분이 할 일은 위 식을 통해 주어진 문자열의 해시 값을 계산하는 것이다. 그리고 이 함수는 간단해 보여도 자주 쓰이니까 기억해뒀다가 잘 써먹도록 하자.
입력
첫 줄에는 문자열의 길이 L이 들어온다. 둘째 줄에는 영문 소문자로만 이루어진 문자열이 들어온다.
입력으로 주어지는 문자열은 모두 알파벳 소문자로만 구성되어 있다.
출력
문제에서 주어진 해시함수와 입력으로 주어진 문자열을 사용해 계산한 해시 값을 정수로 출력한다.
Small (50 점) : 1 ≤ L ≤ 5
Large (50 점) : 1 ≤ L ≤ 50
문제 접근 방법
이번 문제는 자료의 저장과 탐색에 쓰이는 해시 함수의 연산을 구현하는 것이다.
따라서 위에 주어진 해시 함수를 이용하여 해당 변수가 뜻하는 위치에 입력된 값을 넣어주면 된다.
이번 문제의 입력은 총 두 가지를 먼저 고민해봐야 한다.
1. 문자열 VS 1차원 배열
나는 굳이 입력을 배열로 받지 않아도 문자열 인덱싱을 통해 문자 하나하나 비교해 볼 수 있으므로 문자열을 통째로 받았다.
2. 조건문 VS 문자열 인덱싱
문자를 숫자로 변환(ai)할 때 조건문으로 어떤 문자인지 구분하여 숫자를 배정하는 것보다 문자열 인덱싱을 통해 ascii코드를 이용하여 바로 숫자로 변환하는 방법을 선택했다. (∵ 조건문을 사용하게 되면 코드가 a~z까지의 조건을 다 만들어 주어야 하기 때문에 너무 길어져 가독성이 떨어진다고 생각했다.)
이제 입력을 받았으니 연산을 시행해야 한다.
이 문제에서 주의해야 할 것은 입력이 길어질수록 수가 기하급수적으로 커지기 때문에 다음 내용을 고민해보아야 한다.
1. long자료형 사용 VS BigInteger 사용
BigInteger을 사용하면 숫자 범위에 대한 고민 없이 주어진 연산을 진행해주면 된다는 장점이 있지만
연산 코드가 복잡해져서 가독성이 떨어진다는 단점이 있고,
long자료형을 사용하면 연산을 연산자 기호로 나타내어 가독성이 좋다는 장점이 있지만
자료형의 범위 안에 수를 유지해 주면서 연산을 진행해주어야 한다는 단점이 있다.
연산의 경우 두 가지 모두 코드로 실행해서 결괏값을 도출해 보겠다.
JAVA 코드 풀이
1-1. long자료형 사용 + BufferedReader
import java.io.*;
public class Main {
public static void main(String args[]) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int l = Integer.parseInt(br.readLine());
String str = br.readLine();
long sum = 0;
long power = 1;
for(int i=0; i<l; i++) {
sum = (sum + (str.charAt(i)-96)*power)%1234567891;
power = 31*power%1234567891;
}
System.out.println(sum);
}
}1-2. long자료형 사용 + Scanner
import java.util.*;
public class Main {
public static void main(String args[]) {
Scanner input = new Scanner(System.in);
int l = input.nextInt();
String str = input.next();
long sum = 0;
long power = 1;
for(int i=0; i<l; i++) {
sum = (sum + (str.charAt(i)-96)*power)%1234567891;
power = 31*power%1234567891;
}
System.out.println(sum);
}
}2-1. BigInteger 사용 + BufferedReader
import java.io.*;
import java.math.*;
public class Main {
public static void main(String args[]) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int l = Integer.parseInt(br.readLine());
String str = br.readLine();
BigInteger sum = new BigInteger("0");
BigInteger r = new BigInteger("31");
BigInteger power = new BigInteger("1");
for(int i=0; i<l; i++) {
sum = sum.add(new BigInteger(String.valueOf(str.charAt(i)-96)).multiply(power));
power = power.multiply(r);
}
System.out.println(sum.mod(new BigInteger("1234567891")));
}
}2-2. BigInteger 사용 + Scanner
import java.util.*;
import java.math.*;
public class Main {
public static void main(String args[]) {
Scanner input = new Scanner(System.in);
int l = input.nextInt();
String str = input.next();
BigInteger sum = new BigInteger("0");
BigInteger r = new BigInteger("31");
BigInteger power = new BigInteger("1");
for(int i=0; i<l; i++) {
sum = sum.add(new BigInteger(String.valueOf(str.charAt(i)-96)).multiply(power));
power = power.multiply(r);
}
System.out.println(sum.mod(new BigInteger("1234567891")));
}
}코드 실행 결과
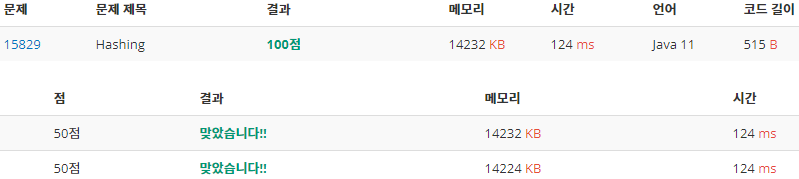
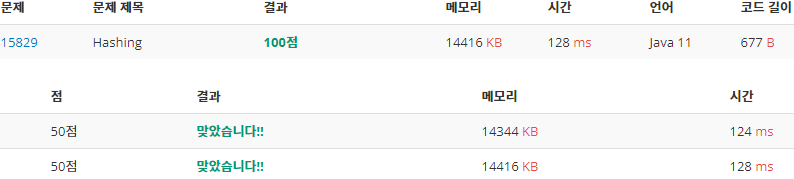
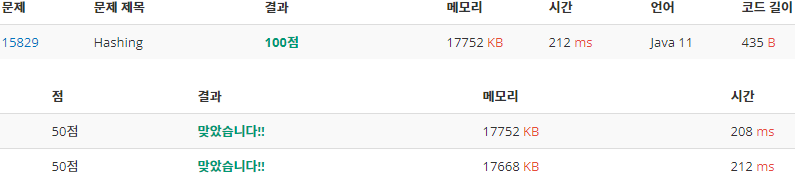
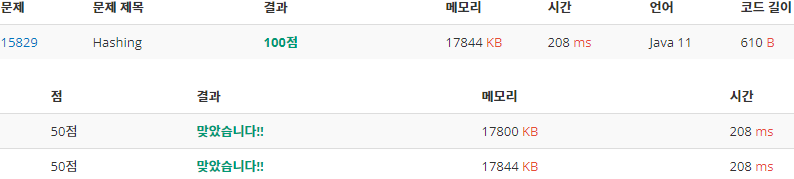
후기
위 결과로 보았을 때, 입력이 그렇게 많지 않아도 Scanner와 BufferedReader함수는 연산 시간에서 유의미한 차이를 보여주고 있다. 반면에 BigInteger와 long자료형을 사용한 각각의 버전에서는 연산 과정이 적어서 인지 연산 시간과 메모리에서 거의 차이를 보이지 않았다. 따라서 이번 문제로는 어떤 경우가 더 효율적인지는 판단할 수 없을 것 같다.
+) 요즘 자료형에 대한 오버플로우 현상이 발생하여 틀리는 문제가 종종 생기고 있다. 입력값이 int형의 범위를 벗어나거나, 입력값은 int형 범위 안이어도 연산 과정에서 벗어나 오버플로우가 발생하여 내가 예상했던 값과 다른 결괏값을 도출해낸다. 이를 사전에 확인하여 자료형을 바꿔줘야 하는데 이게 잘 되지 않고 있다... 숫자 자료형에 대해 다시 찾아보고 이런 실수를 줄일 수 있도록 노력해야겠다.
추후 숫자 자료형의 범위에 관해 포스팅 예정(feat. 오버플로우)
문제 원본
'문제 풀이 > [JAVA_자바] 백준' 카테고리의 다른 글
| [JAVA / 자바] 백준 2751번 - 수 정렬하기 2 (0) | 2022.01.21 |
|---|---|
| [JAVA / 자바] 백준 1920번 - 수 찾기 (0) | 2022.01.20 |
| [JAVA / 자바] 백준 4949번 - 균형잡힌 세상 (0) | 2022.01.18 |
| [JAVA / 자바] 백준 1874번 - 스택 수열 (0) | 2022.01.17 |
| [JAVA / 자바] 백준 10816 - 숫자 카드 2 (0) | 2022.01.14 |